Rick's b.log - 2016/01/06
You are 3.141.35.27, pleased to meet you!
Rick's b.log - 2016/01/06 |
|
| It is the 24th of November 2024 You are 3.141.35.27, pleased to meet you! |
|
mailto: blog -at- heyrick -dot- eu
Consider:
There is actually an order to the entries. They are presented in increasing order of "work done".
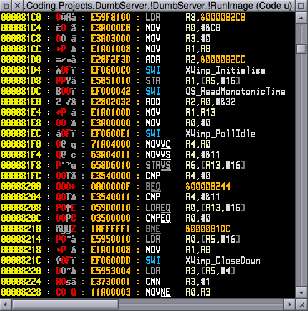
For the inline assembly, the compiler might rearrange a few things in the optimiser stage, but you basically get exactly what you ask for. No, really - here is the wimp polling part of DumbServer:
The "calling a function" version was the least-work-done option prior to inline assembly. It isn't for everybody, as it means making assembler code and linking it with the final program. This isn't something to be feared - huge swathes of many libraries are exactly this.
And finally, we come to the loathing that is
Sure enough...
Here's the code for _swix(). The code is two incarnations - the first is a "StrongARM" type, which means it creates non-self-modifying code to be safe on later processors with split caches (that's all of the modern ones), plus a type for older (legacy) machines that constructs stuff on the stack and runs it.
Ready?
Are you frigging kidding me? For the convenience of making code look a little prettier, you'll run 24 instructions just to call a SWI? And that's the best case. I'll leave it for you to work out the worst case (expecting a register back, and that register being R0...), but really, labels with names like swix_even_more_tedious and swi_beyond_a_joke ought to tell you something.
Finally, many thanks to Colin for clarifying the behaviours of recv() and accept(), especially in the sense of non-blocking. It is always nice to know that there is a simpler way to do something. ☺
Why I loathe _swix()
_swix() is a function in the RISC OS C library that allows one to easily call SWIs. It is small, compact, easy to read.
__asm
{
SWI OS_ReadMonotonicTime
timenow = R0
}
compare with:
timenow = ReadMonotonic();
...plus this in an assembler file...
EXPORT ReadMonotonic
ReadMonotonic
SWI OS_ReadMonotonicTime
MOV PC, R14
and compare with:
_kernel_swi(OS_ReadMonotonicTime, &r, &r);
timenow = r.r[0];
and also compare with:
(void) _swix(OS_ReadMonotonicTime, _OUT(0), &timenow);
_kernel_swi() is fairly simple. I've seen many programs written using _kernel_swi() for most SWI calls, and to be honest if I'm trying out new code I'll often use _kernel_swi() and switch to custom routines later. It is more verbose, especially setting up each register in turn, however it is extremely clear about what is going where. You pretty much don't have to parse _kernel_swi() code, it is self-evident.
Here is the code for _kernel_swi():
|_kernel_swi|
FunctionEntry "a3, v1-v6"
BIC r12, a1, #&80000000
TST a1, #&80000000
ORREQ r12, r12, #X
LDMIA r1, {r0-r9}
SWI XOS_CallASWIR12
LDR ip, [sp]
STMIA ip, {r0-r9}
MOVVC a1, #0
BLVS CopyError ; BL<cond> 32-bit OK
Return "a3, v1-v6"
Basically, we're sorting out the SWI number and pushing it into R12, pulling all of the useful registers off the stack, calling a SWI to call the SWI, pushing the (possibly updated?) registers back, and sorting out error situation or returning zero if no error.
It is at this part that the disassembly becomes harder to read. No modern version of Debugger is able to parse C's branch table, so what you will see is a BL branch to later in the program, and if you follow it, many many lines of MOV PC, #0. If it's the tenth one down, it is _kernel_swi(). Hardly intuitive.
_swix(). In the disassembly, _swix() is much like _kernel_swi(), only it is the final MOV PC, #0...well, at least in the current versions of CLib.
The problem is, _swix() can provide nice tidy lines like this (though, note the use of _INR with R suffix, and _OUT without an R suffix):
(void) _swix(OS_SWINumberFromString, _INR(0,1)|_OUT(0), 0, (int)"My_SWIName", &swinumber);
We are telling the instruction that we are passing two registers (R0 and R1) and we expect a reply from R0. Data tidily follows.
Maybe it is growing up with the BBC Micro? I don't know. I see an instruction like that and I suck air through my teeth and mutter oooh, you're gonna pay for that.
Only the first part need concern us nowadays.
[ StrongARM
; tedious static _swi(x) entry handling, to avoid generating dynamic code, and
; requiring an expensive XOS_SynchroniseCodeAreas
|_swix|
ORR r0, r0, #&20000
TST r1, #&FF0 ; check for use of input regs. 4 to 9, or of block param
BNE swix_even_more_tedious ; if so, do full stuff
STMFD sp!, {r2, r3} ; put 1st two variadic args on stack
STMDB sp!, {r1, r4-r9, lr} ; save stuff
SUB sp, sp, #5*4 ; so we can use tail code common with dynamic version (and room for regs stash)
ADD r14, sp, #(5+8)*4 ; r14 -> input args
MOV r12, r0 ; target SWI code
STR fp, [sp] ; stash fp
MOV r11, r1
TST r11, #&001
LDRNE r0, [r14], #4
TST r11, #&002
LDRNE r1, [r14], #4
TST r11, #&004
LDRNE r2, [r14], #4
TST r11, #&008
LDRNE r3, [r14], #4
STR r14, [sp, #4] ; stash args ptr
LDR fp, [sp, #0] ; get fp and lr saying something useful in case
LDR lr, [sp, #48] ; SWI aborts or throws an error.
SWI XOS_CallASWIR12
LDR ip, [sp, #4] ; restore (ip -> args)
B SWIXReturn
swix_even_more_tedious
|_swi|
STMFD sp!, {r2, r3} ; put 1st two variadic args on stack
STMDB sp!, {r1, r4-r9, lr} ; save stuff
SUB sp, sp, #5*4 ; so we can use tail code common with dynamic version (and room for regs stash)
ADD r14, sp, #(5+8)*4 ; r14 -> input args
MOV r12, r0 ; target SWI code
STR fp, [sp] ; stash fp
MOV r11, r1
TST r11, #&001
LDRNE r0, [r14], #4
TST r11, #&002
LDRNE r1, [r14], #4
TST r11, #&004
LDRNE r2, [r14], #4
TST r11, #&008
LDRNE r3, [r14], #4
TST r11, #&010
LDRNE r4, [r14], #4
TST r11, #&020
LDRNE r5, [r14], #4
TST r11, #&040
LDRNE r6, [r14], #4
TST r11, #&080
LDRNE r7, [r14], #4
TST r11, #&100
LDRNE r8, [r14], #4
TST r11, #&200
LDRNE r9, [r14], #4
STR r14, [sp, #4] ; stash args ptr
TST r11, #&800 ; use of block parameter input?
BLNE swi_blockhead ; if so, handle it and... (BL<cond> 32-bit OK)
TST r11, #&800 ; use of block parameter input? (r11 preserved by the call, flags not)
LDRNE r14, [sp, #4] ; ...restore arg ptr
TST r12, #&20000 ; if non X SWI, could be a return value register
BEQ swi_beyond_a_joke
LDR fp, [sp, #0] ; get fp and lr saying something useful in case
LDR lr, [sp, #48] ; SWI aborts or throws an error.
SWI XOS_CallASWIR12
LDR ip, [sp, #4] ; restore (ip -> args)
B SWIXReturn
swi_beyond_a_joke
;so we have to deal with a return value then
LDR fp, [sp, #0] ; get fp and lr saying something useful in case
LDR lr, [sp, #48] ; SWI aborts or throws an error.
SWI XOS_CallASWIR12
LDR ip, [sp, #4] ; restore (ip -> args)
StoreSWIXFlags
LDR lr, [sp, #1*4]
;right, if R0 is also required as an output param, we'd better sort that first
TST lr,#&80000000
BEQ swi_beyond_a_joke_R0safe
LDRNE lr, [r12], #4
STRNE r0, [lr]
LDR lr, [sp, #1*4]
BIC lr,lr,#&80000000 ;done it now
STR lr, [sp, #1*4]
swi_beyond_a_joke_R0safe
ANDS lr, lr, #&000F0000 ;select return value register
BEQ SWIReturn2
CMP lr, #&00010000
MOVEQ r0, r1
CMP lr, #&00020000
MOVEQ r0, r2
CMP lr, #&00030000
MOVEQ r0, r3
CMP lr, #&00040000
MOVEQ r0, r4
CMP lr, #&00050000
MOVEQ r0, r5
CMP lr, #&00060000
MOVEQ r0, r6
CMP lr, #&00070000
MOVEQ r0, r7
CMP lr, #&00080000
MOVEQ r0, r8
CMP lr, #&00090000
MOVEQ r0, r9
CMP lr, #&000F0000 ;for goodness sake!
LDREQ r0, [sp]
B SWIReturn2
swi_blockhead
STMFD sp!, {r10-r12, lr}
LDR r12, [sp, #(4+1)*4] ;pick up args ptr from stack
;r12 currently -> first output arg, so crank it past them
MOVS r11, r11, ASL #1
ADDCS r12, r12, #4 ;tests R0 output bit
ADDMI r12, r12, #4 ;tests R1 output bit
MOV r10, #5 ;5 more reg bit pairs to go (includes PC and one dummy)
swi_blockhead1
MOVS r11, r11, ASL #2
ADDCS r12, r12, #4
ADDMI r12, r12, #4
SUBS r10, r10, #1
BNE swi_blockhead1
;now r12 -> parameter block args on stack
LDR r11, [sp,#4]
ANDS r11, r11, #&f000 ;select reg for parameter block pointer
MOVEQ r0, r12
CMP r11, #&1000
MOVEQ r1, r12
CMP r11, #&2000
MOVEQ r2, r12
CMP r11, #&3000
MOVEQ r3, r12
CMP r11, #&4000
MOVEQ r4, r12
CMP r11, #&5000
MOVEQ r5, r12
CMP r11, #&6000
MOVEQ r6, r12
CMP r11, #&7000
MOVEQ r7, r12
CMP r11, #&8000
MOVEQ r8, r12
CMP r11, #&9000
MOVEQ r9, r12
LDMFD sp!, {r10-r12, pc} ; no need to restore flags
] ; StrongARM
David Pilling, 11th January 2016, 03:06
| © 2016 Rick Murray |
This web page is licenced for your personal, private, non-commercial use only. No automated processing by advertising systems is permitted. RIPA notice: No consent is given for interception of page transmission. |