Rick's b.log - 2024/06/15
You are 18.119.127.13, pleased to meet you!
Rick's b.log - 2024/06/15 |
|
| It is the 21st of November 2024 You are 18.119.127.13, pleased to meet you! |
|
mailto: blog -at- heyrick -dot- eu
This is a little more than the current behaviour where entering something, like "heyrick.eu" in the navbar will have the browser try https first, because it will - if you explicitly give it an http link - ignore that and try https first anyway.
Most sites that support https will quietly redirect you if you follow an http link. My blog is a little bit different, it will quietly redirect you unless you give a specific date. I explain why this is here, though that's nearly eight years old now and as encrypted everywhere is pretty much assumed by default, I will probably - soon - redirect all http to https... and if crappy public access points try to pwn their users with dodgy certificates, it's on the user to recognise this.
Now, another possible issue is in following http only links, and as a side issue, the use of http only image references leading to an "unsecure" mixed content page (which, depending on browser and settings, may or may not even work).
While the simple answer is to just change all of the "http" in links to be "https", as usual it's not as simple as that. The first reason is that some sites still don't support encryption. While it's free to get an SSL certificate from Let's Encrypt, there are sadly some hosts that still seem to have the idea that SSL is some super-duper premium extra that needs paid for, either for having a certificate or - even worse - for all the complication of setting up the server to support the use of a certificate (even a free one). Honestly, if your business is hosting websites, this ought to be a tick box "does it itself" item by now. It's 2024, not 2014!
The second reason is that of digital decay. These days I listen to, variously, Epic Rock Radio and when I'm in the mood for something a little darker Caprice Symphonic Gothic Metal, and sometimes a bit of Love '80s Manchester.
It is likewise on my blog. Quite a bit of stuff that was written about back in, say, 2010 just doesn't exist any more. So http versus https is not relevant. It's not just 404s, some sites have vanished.
For me, the problem is that RISC OS solutions won't work as very little of my site is on RISC OS (there's no UI-based SFTP client as far as I can see, which is another reason to not use it), I don't start the Windows box much these days, and quite a bit of the blog stuff is split across multiple machines (including Android and, yes, RISC OS) depending on where/when/how I wrote the content. Oh, and what I'm writing now? It's in the same file as the stuff I wrote last time (all that political stuff). In fact, if I go down to the end of the file, it's the article on combination locks from 5th May. What I do after writing the content is just copy-paste it into the blog's article creator.
All of this means that any looking for links really needs to be done on the server side of things.
Luckily, it's a pretty simple job for PHP. The code here is simple. I don't use RegEx or glob() or anything that would take time to explain. And the result is almost the same as that described above. The difference is that the above was set to strip out paths and extensions so as to make it less obvious how this blog actually works behind the scenes.
Now let's look at some code to do the job.
This sets a global string giving the base of the website relative to the server's root directory. Apache normally puts sites in
Next, we'll have a function that, when given the name of a file, will load it, attempt to parse it as HTML, and report on what it finds. There's quite a lot going on behind the scenes here. file_get_contents loads an entire file, loadHTML parses that loaded file into a DOM representation of the loaded file, getElementsByTagName returns a list of each matching tag found, foreach steps through them... Having all of this stuff automagically happen makes the code a lot simpler, so I can present the scan_links function in its entirety and let the comments do the rest of the explanation.
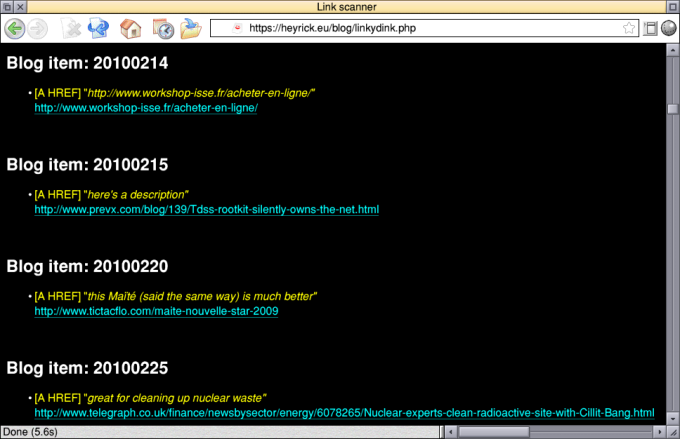
As you can see, when a link is found we'll output "[A HREF]" followed by the text string that the link says (that the user sees), and on the next line the actual link URL, that is made an actual link.
Following this, we will need a routine to look for files to scan, and to also pick up on directories and call itself to scan into them.
And, finally, a call outside of a function that is executed as the script is loaded in order to get the scan going.
That's all. Give this a cute name like linkydink.php and put it on your site with the base path set up correctly, then try to open it in a browser and you should get a report of all of the files that contain either http links or http images.
Here is the code in full. Copy-paste it.
On my site, I have 29 images and 1,138 links using http references. In order to not have to worry about mixed content pages, I have corrected all of the embedded images, which in some cases meant simply replacing them with '#' and leaving an empty space.
As for the links, I know what I am like. I would start looking for alternatives for things that don't exist and that's absolutely not a magical rabbit hole that I plan to fall down. Life is far too short, and I already have about a billion things I'm supposed to be doing that I don't need to make it a billion-and-one.
So what I have done is convert everything that I could since 2020. Earlier stuff will remain as-is and may be a number of dead links or links that now go to domains "parked" for extortionate prices (an interesting one is transcendusa.com is parked, is Transcend no longer a company?).
Not all links could be converted. Those remaining on http-only are: misc.vinceh.com, starfighter.acornarcade.com, 8bs.com, www.stronged.iconbar.com, PlingStore, and various radio streams.
You might spot a theme there, a lot of Acorn/RISC OS stuff. But, then, it might be skewed by my own interests. For instance, there's precious little about Sybian and nothing at all about Plan9. Plus radio streams might not feel that going https is worth it.
Cleaning the digital litter tray
There was some discussion on the ROOL forum regarding browsers now favouring encrypted links, and that plain old HTTP in on the way to being deprecated, with browsers soon to toss away the "http" and force "https". Whether it'll fail or fall back to plain http depends upon the browser and the settings.
As an aside, it is worth noting the comical ballsup that is Google search on Google's Chrome browser on Android. If you search for something, like a PDF datasheet, and it happens to be served from an http only site, then tapping the link will open a new blank window with a load of crap in the URL - all the Google rubbish. You won't get a PDF. You won't get anything other than a blank page.
But if you go up into the navbar and delete all of the Google-guff around the link that you're actually trying to follow and then enter it, ta-dah, you'll get the PDF downloading.
Clearly when Google decided to be obtuse and sulk about links to http-only documents (I don't know if it's the search or Chrome, and as an end user I don't care), they didn't bother to test to see what happens. Because a blank page? User unfriendly and makes Google look like dicks that you have to undo all the Googlage to get to a working URL.
Back just before the world knew the word "Covid", I used to listen to PPN Radio, Gothique13, and Eagle '80s. These days, none of those exist. PPN suffered a hardware failure and never came back, Gothique just stopped broadcasting one day, and Eagle - that I had listened to since 1996 - was bought by the UK's Bauer Media group that geoblocked me (because I'm not in the UK), and latterly did away with the Eagle brand entirely renaming the station something generically awful like "Greatest Hits Radio" which I rather suspect is a "one channel fits all" that has come to replace many of the local stations thus losing any sense of local identity (Eagle used to get involved in a fair number of things in and around Guildford). I cannot listen any more, but I rather suspect the only 'local' part if it left is an opt out for news, weather, and travel info.

Getting a list of links to check.
The top two don't exist any more, the bottom two do.<?php
// LinkyDink v0.01
// Thrown together by Rick Murray
// Saturday, 15th June 2024
// Licence: CDDL
// Set the base directory, global scope.
$base = "/var/www/hosts/yoursite/html";
/var/www but this can be altered depending on the current configuration. If you (S)FTP into your site, it'll probably say somewhere what the actual directory containing your site is called.
You can, obviously, include some extra folders (such as /blog) if you only want to check a subset of the site.
function scan_links($where)
{
// This will load a given file and look for links and images,
// reporting if any are found that use plain http (not https).
global $base; // We'll be wanting this
// We have not output a filename
$title = false;
// Read the file into memory
$html = file_get_contents($where);
// And parse it as a DOM (using '@' to suppress parse errors)
$dom = new DOMDocument;
@$dom->loadHTML($html);
// Look for <a href ...>
$links = $dom->getElementsByTagName('a');
// Sanitise the title
$ttl = substr($where, strlen($base) + 1);
// Iterate through them
foreach ($links as $link)
{
// Get the actual link
$url = $link->getAttribute('href');
// Does it begin with plain ordinary HTTP?
if ( substr($url, 0, 5) == "http:" )
{
// Output a title for this file if we haven't done so yet.
if ( $title == false )
{
echo "<h2>Blog item: $ttl</h2>";
echo "<ul>";
$title = true;
}
// Now output the reference to this file IN YELLOW
// (saying [A HREF], then the link text, and then
// the link itself (which is made into a link...)
echo "<li><font color=\"yellow\">[A HREF] "<i>";
echo $link->nodeValue;
echo ""</i></font><br>";
echo "<a href=\"$url\">$url</a>";
echo "</li>";
}
}
// Now do the same for <img src ...>
$links = $dom->getElementsByTagName('img');
foreach ($links as $link)
{
$url = $link->getAttribute('src');
if ( substr($url, 0, 5) == "http:" )
{
if ( $title == false )
{
echo "<h2>Blog item: $ttl</h2>";
echo "<ul>";
$title = true;
}
// It isn't coloured as there's only the [IMG SRC] text
// to display prior to the link being output.
echo "<li>[IMG SRC] <a href=\"$url\">$url</a>";
}
}
// If something was output, tidy up afterwards.
if ( $title == true )
{
echo "</ul>";
echo "<p> <p>";
}
// And release memory claimed by the DOM and HTML load
unset($dom);
$dom = null;
unset($html);
$html = null;
}
For images, there isn't anything to display (we could output the alt text but this doesn't have much point as it's the image that the user sees...) so we just say "[IMG SRC]" followed by the link URL which is a proper link as before.
In order to make things stand out a little more, the links are coloured yellow while the images are left uncoloured.
So a link looks like this:
While an image looks like this:
http://www.tictacflo.com/maite-nouvelle-star-2009
Something we need to take care of is the Unix/DOS way of representing the current directory as '.' and the parent with '..'. If these aren't excluded (using array_splice) then this will eventually abort trying to scan /var/www/hosts/yoursite/html/./././././././. (actually, a ridiculously long list of slash-dots) which is suboptimal.
We also ignore any folder that begins with a dot, as this means it is something hidden. This only tends to turn up in websites as the file .htaccess, but we'll support dot-prefixed directories just in case.
We scan for files with a .html suffix, as well as .doc. I don't actually use the .doc extension (for one thing, on Windows it would be mistaken as a Word file), it is just there to show how to deal with a four letter extension in case your site uses .htm instead of .html (or if you have a frankensite that uses both).
function get_files($start)
{
// Recursively scan the files in a directory, and if we find a
// .html or .dat file then scan that file for links.
// Get the contents of the directory.
$filelist = scandir($start);
// Discard the '.' and '..' entries.
array_splice($filelist, 0, 2);
// Simple HTML header
echo "<html><head><title>Link scanner</title></head>";
echo "<body bgcolor=\"black\" text=\"white\" link=\"cyan\">";
// Step through each file in turn
foreach ( $filelist as $thisfile )
{
// If it's a directory, call ourselves to scan into it (skip 'hidden' ones).
if ( is_dir("$start/$thisfile") && (substr($thisfile, 0, 1) != '.') )
{
get_files("$start/$thisfile");
}
else
{
// Otherwise, it's a file. Look for links .html and .doc files only.
if ( ( substr($thisfile, -5) == '.html' ) || ( substr($thisfile, -4) == '.doc' ) )
{
scan_links("$start/$thisfile");
}
}
}
// Finalise the output HTML
echo "</body></html>";
}
// Start the scan.
get_files( $base );
?>
<?php
// LinkyDink v0.01
// Thrown together by Rick Murray
// Saturday, 15th June 2024
// Licence: CDDL
// Set the base directory, global scope.
$base = "/var/www/hosts/yoursite/html";
function scan_links($where)
{
// This will load a given file and look for links and images,
// reporting if any are found that use plain http (not https).
global $base; // We'll be wanting this
// We have not output a filename
$title = false;
// Read the file into memory
$html = file_get_contents($where);
// And parse it as a DOM (using '@' to suppress parse errors)
$dom = new DOMDocument;
@$dom->loadHTML($html);
// Look for <a href ...>
$links = $dom->getElementsByTagName('a');
// Sanitise the title
$ttl = substr($where, strlen($base) + 1);
// Iterate through them
foreach ($links as $link)
{
// Get the actual link
$url = $link->getAttribute('href');
// Does it begin with plain ordinary HTTP?
if ( substr($url, 0, 5) == "http:" )
{
// Output a title for this file if we haven't done so yet.
if ( $title == false )
{
echo "<h2>Blog item: $ttl</h2>";
echo "<ul>";
$title = true;
}
// Now output the reference to this file IN YELLOW
// (saying [A HREF], then the link text, and then
// the link itself (which is made into a link...)
echo "<li><font color=\"yellow\">[A HREF] "<i>";
echo $link->nodeValue;
echo ""</i></font><br>";
echo "<a href=\"$url\">$url</a>";
echo "</li>";
}
}
// Now do the same for <img src ...>
$links = $dom->getElementsByTagName('img');
foreach ($links as $link)
{
$url = $link->getAttribute('src');
if ( substr($url, 0, 5) == "http:" )
{
if ( $title == false )
{
echo "<h2>Blog item: $ttl</h2>";
echo "<ul>";
$title = true;
}
// It isn't coloured as there's only the [IMG SRC] text
// to display prior to the link being output.
echo "<li>[IMG SRC] <a href=\"$url\">$url</a>";
}
}
// If something was output, tidy up afterwards.
if ( $title == true )
{
echo "</ul>";
echo "<p> <p>";
}
// And release memory claimed by the DOM and HTML load
unset($dom);
$dom = null;
unset($html);
$html = null;
}
function get_files($start)
{
// Recursively scan the files in a directory, and if we find a
// .html or .dat file then scan that file for links.
// Get the contents of the directory.
$filelist = scandir($start);
// Discard the '.' and '..' entries.
array_splice($filelist, 0, 2);
// Simple HTML header
echo "<html><head><title>Link scanner</title></head>";
echo "<body bgcolor=\"black\" text=\"white\" link=\"cyan\">";
// Step through each file in turn
foreach ( $filelist as $thisfile )
{
// If it's a directory, call ourselves to scan into it (skip 'hidden' ones).
if ( is_dir("$start/$thisfile") && (substr($thisfile, 0, 1) != '.') )
{
get_files("$start/$thisfile");
}
else
{
// Otherwise, it's a file. Look for links .html and .doc files only.
if ( ( substr($thisfile, -5) == '.html' ) || ( substr($thisfile, -4) == '.doc' ) )
{
scan_links("$start/$thisfile");
}
}
}
// Finalise the output HTML
echo "</body></html>";
}
// Start the scan.
get_files( $base );
?>
That being said, I would like to call out PlingStore which is the closest thing RISC OS has to an app store, and I believe also takes payment details (I'm not sure how it works as I haven't purchased anything). Suffice to say, it's a rather poor show that an app store (that also deals with commercial apps) isn't fully encrypted.
Rob, 15th June 2024, 20:35 Rick, 15th June 2024, 21:07
Maybe if I was unemployed and twenty years younger... 😋David Pilling, 16th June 2024, 01:46
Often they are broken because people move files but do not provide redirects - why don't they care.
After that one looks at the wayback machine - and finds it is not perfect, and then when some people removed the link targets they also removed the copies from the internet archive - what are they thinking.
So the total of knowledge on the web is changing, stuff comes other stuff goes.
If I was looking for http links I'd probably use grep (available on the server). I've not removed any http links perhaps I should.jgh, 16th June 2024, 04:38 jgh, 16th June 2024, 05:54 SteveP, 16th June 2024, 10:03
The latter works fine. info about FQDN and relevance of host and domain portions to certificates can sit elsewhere.SteveP, 16th June 2024, 10:06
Because they are Cisco and Microsoft and...David Pilling, 18th June 2024, 03:07
| © 2024 Rick Murray |
This web page is licenced for your personal, private, non-commercial use only. No automated processing by advertising systems is permitted. RIPA notice: No consent is given for interception of page transmission. |
{kind=link}