It is the 1727th of March 2020 (aka the 21st of November 2024)
You are 3.145.93.227,
pleased to meet you!
mailto:blog-at-heyrick-dot-eu
I'm still here!
No blog updates in a long time - that's because I have been busy elsewhere. Not to mention feeling tired a lot for no explicable reason. I guess it's the season - but I'm on holiday now - wheee!
Okay. One of the things I've been busy with is DeskLib, a nice library for RISC OS that offers an event-driven way to write programs for RISC OS. DeskLib has been around for ages and I used it way back when after realising how unpleasant the standard RISC OS library was. I wonder, actually, if the standard library wasn't just a tarted-up version of the libraries that Acorn used to write the base applications (!Draw, !Edit, and !Paint)?
There is an existing modern version of the library available at http://www.riscos.info/index.php/DeskLib as part of the GCCSDK, however the part that caught my eye was "The last AOF release, for use with older versions of GCC (3.4.6) and the Castle C/C++ compiler is 2.80" and "The current version is 3.00, and is ELF-only for use with latest versions of GCC". In other words, the library is going to switch to be ELF only which means it will only work with GCC. The native RISC OS development suite is no longer going to be a supported product.
Discussing this on the RISC OS forums, Steve Fryatt said:
The key point here is that having to maintain RISC OS-specific back-end tools for a compiler that�s already perfectly capable of generating ARM code is massively wasteful in terms of developer resource when all that you actually need is a bunch of off-the-shelf tools that work with the standard ELF format and an unchanging elf2aif tool to convert the end result into something more familiar to RISC OS.
The only real downside is the existence of libraries which are only distributed in ALF format (something that Rick seems keen to perpetuate with his new DeskLib). In practice I�ve never really found this to be a problem in around 15 years of using GCC; if you�re using the DDE libraries, you�re probably using Norcroft anyway.
I�m not sure that there�s any excuse for current developers refusing to build ELF versions of their libraries. The bigger problem is actually going the other way: a GCC-using developer would need to fork out for the DDE to be able to generate ALF versions of any libraries that they wrote.
My reply? Well, first of all, I do not buy the "RISC OS specific back end" argument. The GCC compiler targets a hell of a lot of different platforms. There is little in common between Linux and Windows asides from probably running on x86 hardware - yet the compiler manages. With that in mind, either the compiler is horribly written, or it is designed so that different back ends can be slotted in (and given the frequent use of cross compiling - ARM code built on an x86 box - I would say that the back ends don't even have to match the host platform). With that in mind, surely the back end - once written - could mostly be recycled? I don't believe that this stuff is written over and over again for each iteration of GCC. That said - the choice of library is surely a problem for the linker, not the compiler? I would have thought that the linker would change less frequently...
Next - even though the Norcroft/Castle/ROOL compiler is a commercial product - it is the proper native tool suite for RISC OS and it uses file types that are documented in the PRMs (the back of book four). This stuff has been standardised in print for the past 23 years, with the aim of having a method of making the tools able to be compatible with each other. Nick Roberts wrote ASM (note - probably the last framed site in existence, click on the Misc link), a free (and rather nice) assembler which works with the Norcroft suite and/or alternative linkers (drlink in the 26 bit days) exactly because all of these file formats were described and interoperable.
Now, I do not really care much about whether or not GCC chooses to use ELF as an intermediate stage to producing a valid RISC OS program. What concerns me is that newer versions of GCC are dropping support for AOF/ALF files, which is their decision to intentionally make themselves incompatible with the standard RISC OS tools. Fair enough, it's their decision to make, however personally I feel that the decision to migrate DeskLib - arguably the best library RISC OS has - to be GCC-only is not one that I can agree with. A free compiler suite? Great. A good library to go with it? Great. Incompatible with the Norcroft suite? Uhh... hang on... not so great.
There's a third point raised - Steve asks if there is really any excuse for developers to "refuse" to build ELF versions of the library. Note the emotive word "refuse". Despite all that I have said, I have absolutely no objection to my version of DeskLib being an ELF library in addition to ALF. Why? Simple. Compatibility. If everybody can use it, that's great. But it does have some technical problems, namely:
The need to install GCC. This is a minor thing, for GCC is "packaged" so I presume that downloading the package and whatever dependencies it requires will be sufficient to get me up and running.
Learning an entirely new toolchain. This is medium-minor. I guess at some stage it will be something that would need to be done, but at the moment I really don't have the time. This is, of course, assuming that the compiler can just "build the sources" and that they won't need a load of changes because of quirks and differences in implementation. Which, from experience of various compilers of the PC, is actually rather likely to crop up somewhere. I have around 50 MakeFiles and something like 500 source files which are all built to AOF (object) files and then wrapped up as an ALF (library) file. To be brutally honest, I wouldn't even know where to start...
Now the crowd pleaser - it would appear that the newer versions of GCC may have dispensed with the RISC OS tradition of placing files in directories named 'c' and 's' and writing object files to an 'o' directory; and instead have switched to the ugly filename-plus-extension method used on other platforms (if the DeskLib SVN browser is anything to go by). This would imply that getting DeskLib to build on a newer GCC would require bastardising the source to the sort of ugliness that I hoped I'd left behind in the DOS era.
So, I'm not ruling out an ELF version of my fork of DeskLib. I'm only saying that it will be ALF for as long as I am maintaining it. If there's an ELF version too, then good. If not - kindly point your finger at GCC itself. If something wishes to rebuke standard platform conventions, then it should expect the difficulties that this may raise.
Oh, and yes - I am aware that ALF does not support dynamic linking, but then neither does ELF under RISC OS at the moment.
Another thing to be aware of is that a lot is made of various attributes of ELF such as the fact that the executable version contains the program size and doesn't need all that WimpSlot rubbish. Well, surprise! So does AIF. The Read-only area size plus the Read-write area size plus the zero-init size plus debug size is how much memory the application requires not including malloc() etc (but then ELF likely can't say about that either). The fact that the operating system ignores this information is absolutely no reason to denigrate AIF in favour of ELF - the information has been present for over a quarter century, it isn't AIF's fault if older versions of the OS couldn't be bothered to look at it (RISC OS 5 does - CheckAIFMemoryLimit in FileSwitch.s.FSControl).
I have based my version of DeskLib on the original v2.30 sources (not the GCCSDK version). I had already made a hacky conversion to 26/32 neutral back in 2003; which was then recompiled in 2014 as my applications kept crashing thanks to the earlier (Castle era) compiler's propensity for using unaligned loads by default (dumb decision!).
I used it myself in my own programs, and that was as far as it was going to go. Until I saw that the other one was moving over to being ELF-only.
Now, understand this: DeskLib was originally in the RISC OS 2 days, with various modifications for the enhanced features of RISC OS 3. That would put it as being, equally, a quarter century old. Things don't tend to change much in RISC OS - the latest version of the Desktop looks more or less the same as it always has, only now we can have nicer looking outline fonts in the windows instead of pug-ugly VDU text.
That isn't to say that there isn't a heck of a lot of stuff that DeskLib is missing out on now. The Wimp has nicer (more intuitive) error prompts available, we have moved way beyond MODE numbers for selecting what display we would like, and are now using xres×yres×colours (or the pointy-clicky equivalent with DisplayManager), there isn't one single internet-related function in the entire library, and like much of RISC OS there is still the ingrained assumption that a character equals a byte (which is not true with UTF-8; not that UTF-8 is used much (at all?) in RISC OS thanks to these assumptions being commonplace).
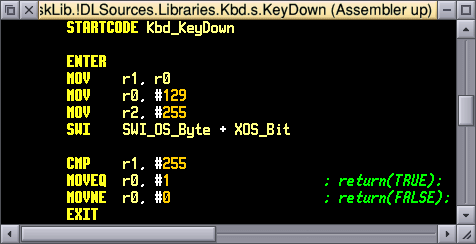
The first task was to revamp all of the 32bitted assembler code to use entry and exit macros wherever possible - this would permit the complexities of saving and restoring processor state to be hidden away in one single place. Better way, some clever use of objasm macros meant I could often enter a function telling it what registers I wanted saved, and then leave simply by calling the "EXIT" macro, and it would restore the appropriate registers. Additionally, these macros do different things if you're building a 32 bit target or a 26 bit target. The end result meaning that the code could be nice and clean and built for the appropriate target without grief (although I'm concentrating on 32 bit (RISC OS 5) at the moment):
The old code had quite the tendency to use STMFD R13!,{R14} which uses the store-multiple to store a single value. Not a big deal on older machines, this and a single register store both take 2N cycles (about 500ns on an ARM2 at 8MHz with the A440's memory).
On the Cortex-A8 (Beagle-xM), three STRs of a single register will take 5 cycles, while three STMs of a single register will take 6 (STM takes at least two cycles). It is only a small thing, but it is worth optimising, as it can add up; especially with the likes of the Cortex-A8 (as in the Beagle xM, for instance) that run dual pipelines and can run instructions in parallel where possible.
Sometimes, however, it was better just to rub the eyeballs and do the minimum necessary. Any more would hurt!
Back to the timings. A number of routines used the stack for register transfer. Fair enough, you could transfer multiple registers quickly as shown in the above example, but there are better ways. Consider the following code:
The BL is supposed to be a SWI call, but I can't get !A8time to recognise it either as SWI or the UAL SVC, so I dropped in a BL instead. We just want to know how long this code takes.
Here's the result:
Cycle Pipeline 0 Pipeline 1
================================================================================
1 STMFD sp!,{r0-r1,lr} blocked during multi-cycle op
2 STM (cycle 2) need pipeline 0 for multi-cycle op
3 LDMFD sp!,{r1-r2} blocked during multi-cycle op
4 LDM (cycle 2) MOV r0,#512
5 ADD r0,r0,#33 need pipeline 0 for next op
6 BL &8000 MOVVC r0,#0
7 LDMFD sp!,{pc} blocked during multi-cycle op
8 LDM (cycle 2) blocked during multi-cycle op
9 LDM (cycle 3) blocked during multi-cycle op
10 LDM (cycle 4)
In honesty, it probably takes 11 cycles. I can't imagine pipeline 1 honestly doing anything while either a BL (or a SWI) is executed as these will branch off to other code. The big surprise is how many cycles are needed to pull the stack and write it to PC.
Cycle Pipeline 0 Pipeline 1
================================================================================
1 STR lr,[sp,#-4]! MOV r2,r1
2 MOV r1,r0 MOV r0,#512
3 ADD r0,r0,#33 need pipeline 0 for next op
4 BL &8000 MOVVC r0,#0
5 LDR pc,[sp],#4 blocked during multi-cycle op
6 LDR (cycle 2)
11 down to 7 might not seem like much, but it is about 36% less - over a third. Expand this to count for all of the functions and all of the times that they may be called... its a lot.
For what it is worth, here's a breakdown A440 (8MHz ARM2) style:
Not quite the third faster as on the Cortex-A8, but with only a single pipeline we're still looking at a mite over a 25% increase in speed, simply by writing the same thing in a more optimal manner.
Note that BL and SWI both take 2S+1N to execute, plus whatever time is necessary to do the task. We're only interested in the code right in front of us.
That painful code? I gave it a whirl:
Cycle Pipeline 0 Pipeline 1
================================================================================
1 MOV r12,sp need pipeline 0 for multi-cycle op
2 STMFD sp!,{r0-r7,lr} blocked during multi-cycle op
3 STM (cycle 2) blocked during multi-cycle op
4 STM (cycle 3) blocked during multi-cycle op
5 STM (cycle 4) blocked during multi-cycle op
6 STM (cycle 5) need pipeline 0 for multi-cycle op
7 LDMFD sp!,{r1-r4} blocked during multi-cycle op
8 LDM (cycle 2) blocked during multi-cycle op
9 LDM (cycle 3) need pipeline 0 for multi-cycle op
10 LDMFD r12!,{r5-r7} blocked during multi-cycle op
11 LDM (cycle 2) can't dual-issue on final cycle
12 MOV r0,#16 output conflict
13 ADD r0,r0,#256 need pipeline 0 for next op
14 BL &8000 LDRVC r12,[r12,#0]
15 wait for r12 wait for r12
16 wait for r12 wait for r12
17 STRVC r2,[r12,#0] MOVVC r0,#0
18 LDMFD sp!,{r4-r7,pc} blocked during multi-cycle op
19 LDM (cycle 2) blocked during multi-cycle op
20 LDM (cycle 3) blocked during multi-cycle op
21 LDM (cycle 4) blocked during multi-cycle op
22 LDM (cycle 5) can't dual-issue on final cycle
You don't want to try the maths for ARM2 style timings.
Update: I was reading the ARM System Developer's Guide on the way into town and noting the instruction timings for more recent processors. So I have inserted this information here.
Thanks to the cache and MMU in, well, every processor after the ARM2 (and definitely the ARM3), we can break the association between processor speed and memory speed. The S and N cycles relate to memory access times. While this will still have an effect, its effect will be mitigated by the cache preloading data, and so on, plus memory is a lot faster these days, so we can start to think of instructions as taking a specific number of cycles - as illustrated by the various timing diagrams above. The older processors didn't have the clever ability to dual-wield pipelines to get more done in less time, but they tried to be more efficient as processors. The thing is, the actual implementation varies, sometimes quite a bit.
Here's a little chart:
Operation
ARM7TDMI
StrongARM
ARM9E
ARM10E
XScale
ARM11E
Cortex-A8
Family
v4T
v4
v5TE(J)
v5TE(J)
v5TEJ
v6J
v7-
Pipeline
5
5
5
5+prediction
7
8+3predictors
13(dual)+prediction
RISC OS
RiscPC era (A7000)
RiscPC era
-
-
Iyonix
Raspberry Pi
Beagle xM
MOV,ADD,...
1
1
1
1
1
1
1 *
LDR
3
1
1
1
1
1-2
1 *
LDR to PC
5
4
5
6
8
4-9
2 *
STR
2
1
1
1
1
1-2
1 *
LDM
2+N
N(>=2)
N
1+(Na/2)
2+N
1+(Na/2)
(Na/2)(>=2) *
LDM to PC
4+N
3+N
4+N
1+(Na/2)
7+N
4-9+(Na/2)
1+(Na/2) *
STM
1+N
N
N
1+(Na/2)
2+N
1+(Na/2)
(Na/2)(>=2) *
B/BL
3
2
3
0-2(?+4?)
1(?+4?)
0-?
1 *
SWI
3
???
3
???
6
8
??? *
Where:
'N' is 1 cycle per register to load or save;
"Na" means registers are loaded in pairs once dual-word aligned (1 per cycle otherwise);
"(>=2)" means instruction takes at least 2 cycles minimum;
"???" means information was missing from the book (!);
"?+x?" means add 'x' cycles of the predictor mispredicted;
"x-y" (ARM11) means instruction takes 'x' but may take 'y' if internal return stack is empty or mispredicts;
"*" means that instruction cycle counts are going to be fairly random in reality because the dual pipelines may allow the processor to execute multiple instructions in one cycle (as demonstrated above)
It can be seen that restoring PC, mispredictions, and SWI calls are increasingly costly as pipeline sizes increase - up until the massive redesign of the Cortex family. RiscPC era machines could process a SWI in three cycles, the Pi requires eight; the Beagle xM? Potentially one but the Cortex-A8 TRM doesn't actually say!
However do not lose sight of the fact that 3 cycles at 40MHz will be somewhat slower than 8 cycles at 800MHz!
Please also do not take this chart as gospel for working out your own programs. You must consult the datasheet relevant to the processor you wish to optimise for - for example consider the LDM instruction of the ARM11. The chart above is a simplified version. Here's the truth:
If not loading PC, it takes one cycle and you can't start another memory access for (N+a-1)/2 cycles and the loaded register will not be available for (N+a+3)/2 cycles (where 'a' is bit 2 of the address).
If loading PC from the stack (R13), it takes 4 cycles; plus 5 extra if the internal return stack is empty or mispredicts; plus (N+a)/2 cycles; and the register will not be available or (N+a+5)/2 cycles.
If loading PC not from the stack (!=R13), it takes 8 cycles; plus (N+a)/2 cycles; and the register will not be available or (N+a+5)/2 cycles.
There are many more caveats, such as shifted offsets and the like which effect timings, that have been omitted from this table.
Finally, I shall leave you with two chunks of code. The first is DeskLib showing its age by jumping through extraordinary hoops to save and restore the FP context around calls to Wimp_Poll (even though most applications probably didn't require this). Ready? Here we go...
And now, since I have officially declared RISC OS 2 as no longer being supported (and quite likely RISC OS 3.10 too), I can take advantage of the fact that the Wimp has been able to do this for a quarter of a century. As such, here is my rewritten code. Spot the difference. It's a real WTF moment...
PREAMBLE
STARTCODE Wimp_CorruptFPStateOnPoll
; Does nothing - FP state is always saved - by the Wimp too...
MOV pc, lr
STARTCODE Wimp_SaveFPStateOnPoll
; Does nothing - FP state is always saved - by the Wimp too...
MOV pc, lr
STARTCODE Wimp_Poll3
; greatly simplified poll routine
; extern os_error *Wimp_Poll3(event_pollmask mask, event_pollblock *event, void *pollword);
ORR a1, a1, #1<<24 ; FP state always saved
ADD a2, a2, #4
MOV a4, a3 ; is this actually used?
SWI SWI_Wimp_Poll + XOS_Bit
STRVC a1, [a2, #-4]
MOVVC a1, #0
[ {CONFIG}=32
MOV pc, lr
|
MOVS pc, lr
]
STARTCODE Wimp_PollIdle3
; greatly simplified poll idle routine
; extern os_error *Wimp_Poll3(event_pollmask mask, event_pollblock *event, int earliest, void *pollword);
ORR a1, a1, #1<<24 ; FP state always saved
ADD a2, a2, #4
SWI SWI_Wimp_PollIdle + XOS_Bit
STRVC a1, [a2, #-4]
MOVVC a1, #0
[ {CONFIG}=32
MOV pc, lr
|
MOVS pc, lr
]
Well... That was nerdy, wasn't it?
So, DeskLib is coming along. Slowly, yes, but I'm dragging it kicking and screaming into the 21st century. I have put up a build of the new version here, as well as a big list of my plans and the various changes made along the way.
I hope that there are still RISC OS programmers using DeskLib, and that they will consider using my version on the new generation of machines.
I feel like I ought to end by saying: Yoroshiku Onegaishimasu!!!!!!!! ☺
Your comments:
Please note that while I check this page every so often, I am not able to control what users write; therefore I disclaim all liability for unpleasant and/or infringing and/or defamatory material. Undesired content will be removed as soon as it is noticed. By leaving a comment, you agree not to post material that is illegal or in bad taste, and you should be aware that the time and your IP address are both recorded, should it be necessary to find out who you are. Oh, and don't bother trying to inline HTML. I'm not that stupid! ☺ ADDING COMMENTS DOES NOT WORK IF READING TRANSLATED VERSIONS.
You can now follow comment additions with the comment RSS feed. This is distinct from the b.log RSS feed, so you can subscribe to one or both as you wish.
VinceH, 27th July 2015, 20:16
Nick's isn't the last remaining Frames-based site - it isn't even the last one for RISC OS; two others that spring to mind are R-Comp and Archive Magazine!
Gavin Wraith, 28th July 2015, 21:55
in a more optimal manner Ouch! I think you mean "better". on the page linked at the top ?? What link ?? Using NetSurf (3.4 #2865). I cannot see any links at the top.
Rick, 29th July 2015, 00:17
Well spotted! I forgot my own links. DUH! They have been added.
As for "more optimal manner", no, I meant exactly those three words. "Better" works for the layman, but is ambiguous as to WHY it is better. More optimal suggests that the goal here is to make the code do the same thing in fewer cycles.
It looks like you're using Textile markup (!), so I've swapped the _underscores_ for italics for you, since I had WinSCP running and, well, it just looks better doesn't it? ;-)
This web page is licenced for your personal, private, non-commercial use only. No automated processing by advertising systems is permitted.
RIPA notice: No consent is given for interception of page transmission.