It is the 1697th of March 2020 (aka the 22nd of October 2024)
You are 18.119.119.195,
pleased to meet you!
mailto:blog-at-heyrick-dot-eu
RISC OS internationalisation
RISC OS has never really had "good" support for foreign languages. That isn't to say the system is incapable, it is more that the API is woefully incomplete. This is a shame, because RISC OS 3 introduced "MessageTrans" which made it fairly simple to load different resources depending upon the desired language(s).
Unfortunately the first hindrance is that the way to choose a "language" is based upon the older (Arthur/RISCOS2 era) method of selecting countries. Today, entering *Country France will switch the system to French (if such resources exist) and set your keyboard mapping to AZERTY.
Good, right?
This is actually a hindrance because what language would Belgium be? How about Switzerland? How do you specify you would like Breton or Gaelic resources? [um, you can't!] Acorn cheated with Canada and split it into two "countries" (the French speaking part, and the English speaking part).
The next hindrance is that the answer to our problems, the Territory module, is not much better. It can accept a variety of options for a given "Territory", such as days of the week in the local language, but all of the formatting and such is fixed. If I would like what is basically the UK territory with the Euro sign for currency, and YYYY/MM/DD date format, I need to build my own territory and load it [plus making my patched Territory a clone of an existing Territory as adding something new is, frankly, an exercise in self-flagellation]. Perhaps in the RISC OS 3.10 days, this would suffice. That Acorn never made this configurable by the time RISC OS 3.5 rolled around is shameful. That we're still saddled with this lack of configurability today is simply awful.
There is another consideration. That is, the difficulty of replacing existant messages with something in a different language when the OS is hardwired to speak English. Admittedly, you have to buy a French version of Windows to get Windows to speak to you in French - but seeing as RISC OS references most of its messages by a tag, it is ludicrous that there is no real mechanism to change what this tag refers to on the fly.
As it happens, I am looking into the viability of patching MessageTrans with a "hidden API" to allow message files to be changed without the application concerned noticing. This, if it works, should permit RISC OS (with its baked in English messages) to be updated at runtime to speak a different language. Furthermore, it may work for apps (templates, menus, and such) if we can get this done before the Desktop world is started.
If not - you can have apps in your preferred language, but the OS will stay in English.
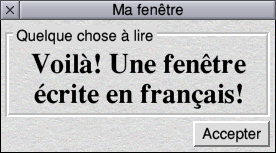
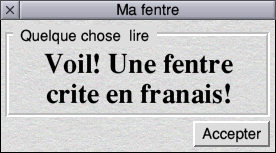
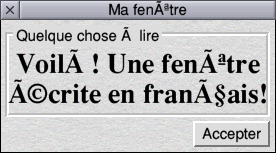
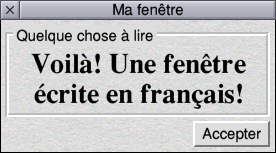
There is, yet, a further wrinkle to this. Consider these:
Latin text on a Latin system
Latin text on a UTF-8 system
UTF-8 text on a Latin system
UTF-8 text on a UTF-8 system
RISC OS is (slowly) gaining support for UTF-8 encodings. TThe font manager can display suitable texts, so you can - on RISC OS - read Japanese web pages and such using NetSurf. However there are many pieces missing from the pie - for instance FontManager cannot substitute fonts if the glyph is out of range for the selected font (anything that wants to be able to display Kana or Hebrew or such in-line with Latin text will need to "reinvent the wheel" for this behaviour), and nothing yet appears capable of correctly moving the caret over UTF-8 characters (so many things assume 1 byte = 1 character, which falls apart when 3 bytes may be one character!).
But we're getting there...
Not quite there, but it mostly works.
Text from Japanese language Wiki page for Noragami.
If RISC OS is to have greater appeal outside of the English-speaking community, internationalisation is something that will need to be taken into consideration, and soon.
To be honest, I think the best method is to throw away the Country/Territory system and write something better. As I'm not volunteering, we'll just have to work with what's there, now. Steve Drain is working on a proposal that will use ISO codes for languages (a better idea than country names). I'm not sure how this would go for backwards compatibility, he hasn't shared anything with me yet - although I look forward to trying out his ideas. It is working within the framework of the existing system for as woefully deficient as it is, to tear it out risks breaking all manner of things.
For what it is worth, however, I would like to make some suggestions for the future:
First of all, we absolutely need FontManager to cope better with invalid UTF-8 sequences. Currently, void spaces appear (a zero width character). Now the lame proposal is to plot an empty square. A much better and more useful proposal would be for invalid UTF-8 sequences to be assumed to be ISO8859/1. If this is done, half of the above problems will go away for older (ISO 8859/1) apps can run on a UTF-8 system and the characters will still appear.
Secondly, FontManager also needs to be smarter about its handling of UTF-8 characters. NetSurf, for instance, is able to tell what code points are defined in which font and to switch to a font that supports extended characters. FontManager needs to be capable of doing the same so if the user selects to write something in Trinity.Medium and throws in some Kana, then FontManager will switch to a font that contains the characters - CyberBit for instance - on the fly and by itself.
The cursor/caret handling needs to be updated to permit better caret positioning, selection highlighting, and string lengths. It is no longer valid to assume that one byte equals one character, so we need OS routines to return both the virtual length (length of text) and the physical length (number of bytes). I don't know what !Edit does, but it's a horrible mess with UTF-8 text.
Ticky-tock!
For a while at work, in our break room, we had a large clock that synchronised with the time signal broadcast from Germany (DCF77).
All was good until some twat threw an orange at it (at least, that's what it looked like). It fell off the wall and the glass front broke. I hung it back up, but there was always something of a disparity between what that clock said and what our clocking-in machine said (but that is a whole different story) so eventually it was replaced with a bog-standard cheapo clock.
The other day, I saw the clock in a bin outside where maintenance dump things like discarded light fixtures and such. It was soaked, having endured three storms (Ruth, St´phanie, Tini) and in the middle of a third (Ulla). It looked so sad.
I asked my line manager if I could take it home. She said it wasn't her decision, go ask the boss.
I asked the boss. He gave me a big smile, the sort that people reserve for "you're weird!" moments, and said he had no problem with that.
Thankfully the maintenance men recuperated the battery before chucking it.
So I took it home, removed all the broken bits of glass, and stripped it down to cogs and circuit boards. I then left the pieces in the sun for a couple of days.
Afterwards, time to put it all back together and see if it works. With a battery fitted, the second hand zoomed around to the home position (12), and afterwards the minute hand whizzed round and round until the clock read 12. It's a shame time doesn't pass that fast while I'm at work! It then sat there doing nothing.
We went out.
A few hours later we returned home. The clock was showing the correct time.
I have put it together without a front panel, but I reckon a piece of Perspex could be cut to fit without too much difficulty. I wonder why nobody at work thought to do this?
Well, the clock has a new life, on my wall, to report the exact time to the second, should such accuracy ever be necessary in my life.
ARM code optimisations
This is mostly an exercise in ways to code more effectively and efficiently for the processor. There's a certain amount of "What's the point?" when you consider that we're trying to avoid pipeline stalls while the system is switching tasks hundreds of times per second, plus dealing with interrupts from clocks, video system, USB, etc thousands of times per second.
Why do we care? Simple. If we gave up caring about the little details, we'll quickly end up like Windows where apps that used to fit on a few floppies now come on DVD-ROM... or iOS apps that seem simple yet require many megabytes. Case in point - the AccuWeather app. Data consists of 11MB, the entire app (plus data) is 98MB. Huh? An FTP program, 30MB (for a flamin' FTP program? are you kidding?). 14MB for a calculator app. Okay, granted, these contain images and data resources and are in some Java-like executable format. But the point still stands, many apps (both iOS and Windows) are inordinately oversized. Because, clearly, resources exist to be wasted.
Or you can, to quote Apple - think different.
But - hold on... what is this?
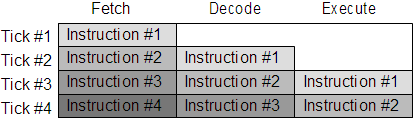
Back in the old days when the ARM was a simple processor and few offered any sort of cache, the typical sequence of instruction execution was to pull some data from memory, interpret it, and act upon it. These are the traditional three stages of a pipeline, for it is clear that when a processor is "doing something", it can also be retrieving the next instruction from memory. This helps throughput, as the next instruction will be ready for the execution unit when it has finished with the current one. These stages are Fetch (to retrieve the instruction, and update PC), Decode (to interpret what the instruction is and set up the control signals accordingly), and Execute (to perform the desired action - which can include reading registers, doing ALU stuff, and writing back updated registers). If the instruction does not Load/Store, most instructions should complete with every clock tick (although MUL alters things somewhat). If the instruction accesses memory, the address is handled by the Execute stage taking two ticks (one to calculate the address, and one to write the data), which will cause a pipeline stall.
The three stage pipeline was implemented in all early ARM processors (up to ARMv7 TDMI):
There is a problem with this scenario. The first, and the most obvious, is the branch instruction. A branch or jump will distrupt the processing and require the pipeline to be flushed. This is because the processor will keep loading instructions sequentially, but if a branch is taken, the part-processed instructions will need to be thrown away. Here's why:
The solution to this is to try, as much as is possible, to use conditional execution to minimise the requirement to branch. Some later ARM processors (most of the contemporary ones) incorporate forms of Branch Prediction.
Branch Prediction is an interesting topic in its own right. There are two primary methods of Branch Prediction. The first method is to try to determine which path will be taken. This can be something simplistic such as "backward branches are always taken, forward branches are not", while alternatives can be a table of branch entries and what happened (this is what the Cortex-A8 uses, for instance), right up to heuristic algorithms that attempt to guess what will happen, with the processor learning along the way. Obviously, the more complex the analysis, the more complicated the processor internals.
The second method of Branch Prediction is the one technically known as cheating. In this situation, the processor will begin executing both branch directions in parallel, and when the result is known, will discard the incorrect option and continue processing the correct option. This does, accordingly, make for a particularly complex processor and is perhaps better suited to CISC processors which would greatly benefit from a minimised pipeline flush requirement, given the pipelines can be extraordinarily long. A Pentium 4 class processor can have a pipeline some 20 stages long, while the winner of the commercial production CPU's most-epic-pipeline award goes to the Pentium D with its 31 stage pipeline. Trust me, while the aim is to have one instruction complete every cycle, you don't want to have every branch flush the pipeline for while an instruction may complete every clock tick, it is going to hurt if it takes 20-31 ticks to get through the pipeline.
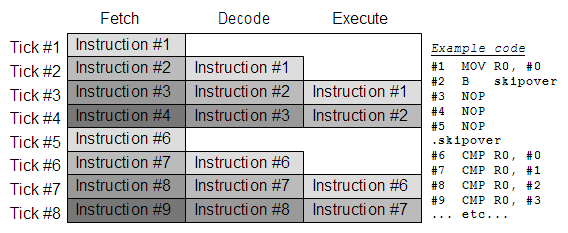
Why is this important? Because modern ARMs no longer use a three stage pipeline. They mostly use a five (or longer) stage pipeline. As was mentioned above, a three stage pipeline will cause a stall when accessing data. This is because the processor only has one data port, so it cannot access memory and load an instruction at the same time. This is what happens:
Basically, the pipeline is suspended, the Fetch and Decode are inactive, holding the previous data, and permitting the processor to access memory on the second Execute stage.
By the way, if you ever wondered why PC points two instructions beyond the instruction that is currently being executed on original-ARM, this is why. The instruction being executed is at the end of the pipeline, while PC deals with the data entering the start of the pipeline.
There are ways to improve performance. The ARM processor did not see particularly large gains in speed in the Acorn era. We started with an 8MHz ARM2, went to a 25MHz ARM3, a 20-33MHz ARM6, and a 40MHz ARM7. The ARM8 was to clock in around 80MHz but it was the loser in a curb stomp battle with the StrongARM that weighed in at 100-200ish MHz (some could be overclocked to squeeze out a little more oomph).
As an interesting anecdote, the Alpha variant of the A5000 contained an ARM3 clocked at 33MHz. The first version of the RiscPC contained an ARM610 clocking 30MHz. Um... Even so, the slower RiscPC managed 37,743 Dhrystone/sec vs 22,809 for the faster clocked A5000 due to other architectural differences (speeds from acorn.chriswhy.co.uk).
These days, the Pi clocks 700MHz nominally (but can happily run at 800MHz and may even push 1GHz if you treat it nicely but push it hard). The Beagle xM clocks 1GHz. But let's ignore ARM dev boards and just look to any Android mobile phone. It probably runs an ARM and speeds of 1.7GHz are not uncommon these days, with pricey lux-lux phones and tablets offering clock speeds in excess of 2GHz. Taiwan Semiconductor (TMSC) has prototyped an ARM core clocking over 3GHz. So we're on fire (in a Katniss sort of way) these days, eh?
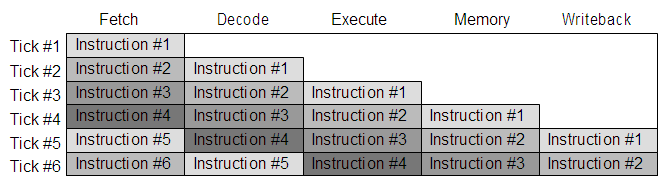
While reductions in process size and increases in memory speed and caching and such can make huge differences, so too can the pipeline. You see, the most you can push a processor core is determined primarily by the speed of the slowest part of the pipeline. From the ARMv4 (ARM8+) until the ARMv5 (prior to ARM10), the pipeline was split into five parts. We shall discuss this because it represents the primary reasons for change from the older style, while having diagrams that don't look ridiculous.
The first change is to use separate data and instruction caches. Whilst this is hell for self modifying code (code for execution will be in the code cache, code modified as data will be in the data cache, expect time-costly cache flushes), it instantly resolves the problem of accessing instructions while accessing memory. By having ports to both caches, the processor can access both at the same time. Obviously this can stall in the case of cache misses, but it's possibly part of the reason why the ARM7 clocks 40MHz (the forgotten ARM8 clocking 72MHz) while the StrongARM rolls in with 100s and trounces everything. ARM learned that lesson, for every production chip subsequently has split caches.
Now, I said above that the slowest part of the pipeline will be the bottleneck. The solution is to identify the slow parts and break them in to smaller sections. Therefore, since the instruction Decode stage is fairly simple in comparison to the Execute stage, reading the registers required has been moved to the Decode stage. The Execute stage itself has been split up into three parts so that each part, overall, does less work, and therefore the pipeline is more balanced in how it operates. The first Execute stage is the ALU to do maths stuff (including address calculations). The second stage is a Memory stage to access memory (or a second multiply stage as multiplication takes time), and the third stage is a Writeback which will write results back to the registers.
Here's a diagram of the five stage pipeline:
As you can imagine now, a branch will be somewhat costlier. A branch will take several more cycles due to a larger pipeline to flush.
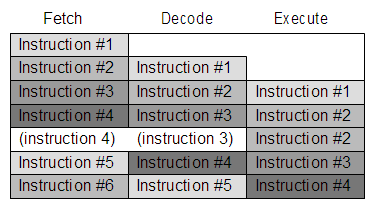
This raises another question - namely - if the results of an instruction are written at the Writeback stage, what happens when the register is needed to be read in the Decode stage. Namely, how can this work?
LDR R0, [R1]
ADD R0, R0, #1
STR R0, [R1]
If we think about our stages, we know that the first LDR is critically dependent upon the Memory stage. Until then, the data to be loaded into R0 does not exist within the processor core. Therefore, a pipeline stall is inevitable. The ADD will need to be held back until the data is available. Likewise, the STR writes R0 which depends upon the results of the ADD.
The ARM processor will automatically deal with these situations by either stalling the pipeline (unavoidable for the LDR) and/or forwarding register data to instructions earlier in the pipeline to avoid a stall occurring. The exact methods used do not appear to be documented that I have been able to determine, so it isn't easily possible to say exactly how this behaves. It is further complicated by processors such as the Cortex-A8 having two pipelines that are interdependent.
I will not go into details, suffice to say that later ARMs have larger pipelines as the stages are broken down into smaller chunks. This makes Branch Prediction more necessary, as a branch with no prediction (or a prediction fail) will cost 13 cycles on a Cortex-A8.
At any rate, for reference:
Ancient ARM (ARM1/2/3/250 - Archimedes family) has a three stage pipeline.
ARMv3 (ARM6/7/7500 - RiscPC, A7000, various clones) has a three stage pipeline.
ARMv4 (ARM7TDMI - widely used in PDAs/older embedded) has a three stage pipeline.
ARMv4 (StrongARM - RiscPC option) has a five stage pipeline.
ARMv5 (ARM926 - my PVR (TI DM320)) has a five stage pipeline.
ARMv5 (ARM10) has a six stage pipeline.
ARMv5 (XScale - Iyonix) has a seven stage pipeline.
ARMv6 (ARM11 - RaspberryPi) has an eight stage pipeline (details here).
ARMv7 (Cortex-A8 - Beagle/xM, IGEPv2, Pandora) has a 13 stage superscalar pipeline; that means it can often execute two instructions at once if they do not depend upon each other's data.
ARMv7 (Cortex-A9 - Pandaboard, Exynos 4xxx) has a 13 stage (?) pipeline that is superscalar, can execute out-of-order to better arrange dependencies, and can speculatively execute both paths of a branch to see which is actually taken.
ARMv7 (Cortex-A15 - Arndale, Exynos 5xxx) is all of the above on a 15-24 stage pipeline. Yikes.
So how can we apply this to our code? We want to try to avoid the latency of pipeline flushes, and also stalls caused by data dependencies.
As much as possible, use conditional execution in preference to branching. A conditional non-executed instruction will pass as a NOP. A branch without prediction (or prediction miss) will be quite a lot costlier.
Know that instructions that modify PC or the CPSR will, in general, not be subject to branch prediction. These will cause a pipeline flush. [specifics]
If possible, load data from memory several instructions before when you need that value. This means the pipeline won't need to stall awaiting the data.
Ditto for 'difficult' instructions (any of the multiplies).
Obviously this is only possible to a degree. For instance, a routine that byte-copies a string will need to branch back for each byte, plus reading and writing data which will place dependencies right on top of each other...
It is a braindead byte copy loop that will mess greatly with the pipeline on a system that does not offer branch prediction. We are loading from memory and awaiting the data (stall for at least two cycles) for the next instruction that writes it, then flushing the pipeline for a branch back. Four simple instructions that should pass in four cycles will take potentially eighteen or nineteen cycles per byte.
You are, of course, free to devise other schemes. For simple variable length strings from variable memory locations, there isn't much you can do really. For longer wodges of data, it may be good to chunder through byte-copy until the address is word aligned, and then word-copy until there is less than a word's worth of data remaining, then byte-copy the tail.
An example with real code, this taken from my ResFinder software:
; Now, to determine the language.
CMP R8, #ARG_ISSET ; "-useos" set?
BNE use_territory ; if NOT, go to ask Territory module
; else fall through to ask the OS
MOV R0, #OSB_RW_COUNTRY ; Read country number
MOV R1, #JUST_READ_COUNTRY
SWI OS_Byte
CMP R1, #IS_DEFAULT ; was it "Default"?
MOVNE R0, R1
BNE country_to_name
MOV R0, #OSB_RW_KEYALPHA ; Read keyboard
MOV R1, #JUST_READ_KEYBOARD ; (shonky last ditch attempt)
SWI OS_Byte
CMP R1, #IS_DEFAULT ; sanity check it!
MOVEQ R1, #IS_UK ; (4=UK)
MOV R0, R1 ; we need this to be in R0
CMP R0, R0 ; set an EQ state to skip following SWI
use_territory ; and save having to have a branch. :-)
SWINE Territory_Number
country_to_name
MOV R12, R0 ; keep a copy for later
ADRL R1, terrname
MOV R2, #16 ; buffer length
SWI Territory_NumberToName
At the start of this code is a test to see which method should be used to read the current "language". It is anticipated that "-useos" will be the more common case, so this fails the conditional test and falls through to the following code without a branch. If the Territory module is to be asked, this then takes the branch.
However, where it becomes interesting is at the end of the -useos code. If you recall, the evaluation for the branch was a not-equal (BNE). Therefore, we can omit having to branch over the now-unwanted Territory SWI call by making it conditional on not-equal (SWINE) and just prior in the -useos code, comparing a register with itself (which will force the flags to an equal condition).
You'll notice I comment copiously. I've had the horror of trying to work out code written by other people who don't bother to comment...and worse, in one case realising that it was my own code but being many years since I last saw it, it no longer made sense. I err on the side of overcommenting. Writing too much might make a person seem like a bit of a twat. What one seems like if they don't bother to comment (especially if the code uses obscure variable/function names) is a phrase that would make my blog fail a PG rating. You get the idea, right? (^_^)
Chokey-chokey?
I had the week off work. We only got a single week for Christmas, so now we must make up holiday time to zero the counter by the end of March. It's a damn shame I can't roll over, but, well, the law says that is not possible.
Anyway - the weekend and Monday were lovely and sunny. Beautiful days.
By Tuesday, a weird sort of haze has started to form, which by Friday was disturbingly visible everywhere.
To cut a long story short, the cold nights and warm days with a high pressure system following a period of unpleasant wet weather was creating a strange situation where water vapour would mix with airbourne particles and force them down towards ground level. In several places the pollution has been measured at 110µg/m³ around here, and higher (I think about 145) in Paris. That is twice/thrice the normal 'limit', and in both cases over the 100µg/m³ limit where the government starts to pay attention.
In numerous cities, public transport is "free" to encourage people to not drive and make the matter worse. Rennes, amongst other cities, have taken the unusual step of reducing speeds on the ring roads to 20kph (about 12.5mph!). I guess this is to annoy drivers into not going anywhere, because it is a speed that isn't the most efficient for the car (leading to more pollution) and by keeping slow moving traffic on the ring road, that extra pollution will be right around the city. Can we say "Duh!"? Of course, Karma has a way of biting you on the ass - and in the case of Rennes, on the south of the ring road at around 7pm today, a goods lorry caught fire belching huge amounts of smoke into the air and blocking the road for almost two hours. I'll leave smirking to your own discretion.
Suffice to say, we might all be wearing face masks Japanese style if this keeps up. But hopefully it'll rain before we reach Beijing style pollution.
Here's a photo. It is about 6pm, the sun would still be in the sky if you could see it. The ground is dry, that isn't fog. That's just a lot of crap floating in the air. It's enough to make you feel ill just looking at it. So I stayed inside and drank numerous cups of tea...
Your comments:
Please note that while I check this page every so often, I am not able to control what users write; therefore I disclaim all liability for unpleasant and/or infringing and/or defamatory material. Undesired content will be removed as soon as it is noticed. By leaving a comment, you agree not to post material that is illegal or in bad taste, and you should be aware that the time and your IP address are both recorded, should it be necessary to find out who you are. Oh, and don't bother trying to inline HTML. I'm not that stupid! ☺ ADDING COMMENTS DOES NOT WORK IF READING TRANSLATED VERSIONS.
You can now follow comment additions with the comment RSS feed. This is distinct from the b.log RSS feed, so you can subscribe to one or both as you wish.
This web page is licenced for your personal, private, non-commercial use only. No automated processing by advertising systems is permitted.
RIPA notice: No consent is given for interception of page transmission.